引言
近几年我们在讨论 AI 能力时,经常会看到“skill”“能力模块”“tool”等词。尤其在面向产品化、流水线化和多模态场景下,把 AI 能力拆成可组合、可复用的“skill”成为一种重要范式。本文旨在系统讲解“AI 的 skill 是什么”,它与模型、任务和工具的区别与联系,如何设计、评估与落地。
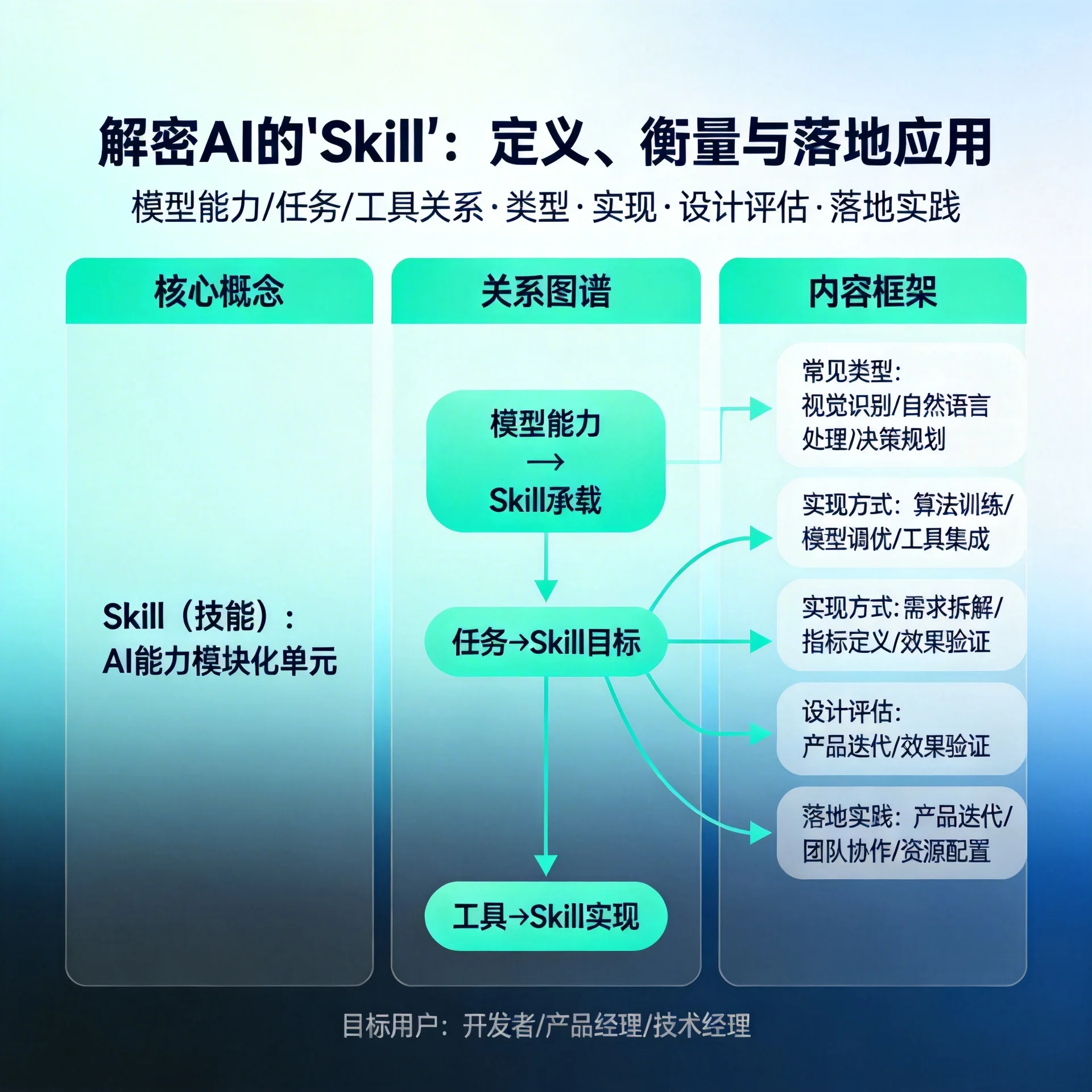
什么是 AI 的 skill?
-
定义:skill(技能)是对 AI 可以执行的具体能力或功能的抽象描述,通常以明确的输入/输出、约束、接口和评估指标来定义。它既不是单纯的模型,也不是单纯的产品功能,而是介于两者之间的可复用能力单元。
-
举例:文本摘要、问答检索、图像标注、代码生成、情感分析、数学推理、数据清洗等都可以被定义为不同的 skill。
-
与“task/任务”的区别:task 更偏向具体业务场景(比如“客服自动回复”),而 skill 更偏向功能性能力(比如“从知识库检索相关段落”)。一个任务可能由多个 skill 组合而成。
-
与“tool/工具”的区别:tool 更强调外部可调用的接口(比如检索 API、数据库、计算器)。skill 可以封装调用外部 tool,也可以仅依赖模型内部能力。
常见的 skill 类型
- 模型内技能:依赖模型本身的推理与生成能力(如翻译、摘要)。
- 工具调度技能:负责调用外部 API(检索、计算、浏览器查询)的封装器。
- 数据处理技能:清理、格式化输入输出(如表格解析、日期标准化)。
- 多步骤/链式技能:将多个 skill 按顺序或并行组合以完成复杂任务(如检索→摘要→格式化)。
如何设计一个好的 skill
- 明确契约:定义输入 schema、输出 schema、边界条件和错误处理。
- 可测量的指标:确定准确率、召回率、延迟、稳定性等评估维度。
- 可组合性:保证接口统一与语义明确,便于在更高层次任务中复用。
- 可观察性:日志、监控、输入输出示例和失败案例记录。
示例(伪 JSON 描述):
{
"name": "document_retrieval",
"input": {"query": "string", "top_k": "int"},
"output": {"documents": "array"},
"metrics": ["recall@k","latency_ms"]
}
如何评估 skill
- 单元化测试:用标准化的数据集和边界样本做离线评估。
- 端到端评估:在实际业务流程中监测 skill 带来的终态指标变化(如用户满意度、任务完成率)。
- 在线实验:A/B 测试不同 skill 实现或参数,观察转化或用户行为差异。
- 鲁棒性与安全性测试:对抗样本、异常输入和滥用场景的检测。
技能组合与编排
实际应用中,复杂任务往往需要多个 skill 的组合。编排策略包括:
- 串行编排(chain):前一个 skill 的输出是下一个 skill 的输入,适合线性流程。
- 并行并聚合(parallel + aggregator):并行调用多个技能后融合结果,适合多来源证据。
- 条件分支(router):根据输入特征选择不同 skill 路径。
要点是处理好接口兼容、错误传播和超时策略。
实战建议与落地注意事项
- 从核心能力开始拆分:优先把对业务影响最大、复用性高的能力抽象为 skill。
- 建立评估流水线:覆盖离线、在线与人工审核三层,以便快速迭代。
- 权衡本地能力与外部工具:将延迟敏感或敏感数据放在可控环境,非敏感或需要最新信息的放在外部检索/浏览工具上。
- 定义降级策略:当 skill 失败时应有回退逻辑(例如简单模板回复或人工接管)。
- 文档化与治理:明确能力边界、隐私策略与合规要求。
对产品与团队的影响
把能力模块化为 skill 有助于团队分工(模型组、工程组、产品组各司其职)、加速复用和提升迭代速度。但也会带来版本管理、接口兼容和多技能协调的复杂性,需要治理策略与自动化流水线支撑。
总结
AI 的 skill 并非单一概念,它更像是一种面向工程与产品的能力抽象:明确契约、可测量、可组合、可观测。把握好 skill 的边界与设计原则,能让 AI 能力更可靠地服务实际业务。实践中从核心能力出发、注重评估与降级策略,并通过良好的文档与治理,能够最大化 skill 的价值。
如果你正在构建或评估 AI 能力模块,建议从一次小规模的技能抽象开始:定好接口、做好测试、上线观察,再逐步扩展组合与优化。